When I first started writing Learning NServiceBus, I was targeting Version 4.0 which, at that time, was still several months away from release. Writing about something that’s still very much in flux is definitely a challenge, and to some extent I was definitely learning as I went.
What really struck me during the writing process was how much easier people learning NServiceBus 4.0 were going to have it than I did when I learned NServiceBus 2.0. The developers at Particular Software (a name change from NServiceBus Ltd – a lot of people seem to think they were bought and this is not the case) are really obsessive about making a powerful framework as easy to use as possible, and I salute them for that.
I remember creating endpoints by hand. Create a new Class Library project. Reference the NServiceBus DLLs and NServiceBus.Host.exe. Build so that the EXE is copied to the bin directory. Go to Project Properties. Set the debugger to run the Host. Create an EndpointConfig class. Add an App.config. Enter a bunch of required XML configuration. OK that’s a lie. As I was once quoted during a live coding demo, “Don’t worry I have been doing this for years. You never write this yourself; you always copy it from somewhere else.” Not exactly a glowing recommendation right?
Then you start debugging and hope you didn’t screw anything up.
NServiceBus 3.x and 4.x changed all that. Now you just reference a the NServiceBus.Host NuGet package and it sets all that stuff up for you. And if you need some bit of config, you can run a helpful PowerShell cmdlet from the Package Manager Console to generate it for you along with XML comments describing what every knob and lever does.
NServiceBus 4.x is a fantastic platform to build distributed systems, but as of the release of NServiceBus 4.0 in July 2013, the big thing still missing was the ability to effectively debug a messaging system (let’s face it, gargantuan log files don’t count) and monitor a distributed system in production to make sure everything isn’t running off the rails.
Well that’s all about to change.
Don’t Build Your Own Monitoring Tools
For the first system I ever built on NServiceBus 2.x, I built my own monitoring and management tools because I had no other choice. I didn’t want to remote desktop into a server and launch Computer Management to view the Message Queues. Let’s face it, that tool is heinous enough when run locally. And I certainly didn’t want to remote desktop into the server to run ReturnToSourceQueue.exe, and have to potentially copy and paste a message id into a console window over remote desktop. No thank you!
So I built a tool called MsmqRemote that had a daemon process that I installed on every single server that hosted any NServiceBus queues. It was responsible for interacting with MSMQ and NServiceBus on each server. It had the capability to list queues, and get details about the messages in each queue, and return all of this information to a client application via a WCF service hosted over TCP. It could move and delete messages, all based on MSMQ code I had to write myself. It contained a copy of the relevant ReturnToSourceQueue code so that it could do that operation as well.
The client application was a WinForms monstrosity with four panes. First you selected a server which was populated from a config file, that told the application which WCF service URL to try to connect to. Then it would ask the server for a list of queues, which would appear in the second pane. After selecting a queue, it would ask for a list of messages, which would appear in the third pane, and finally, selecting a message would again go to the server to ask for message details and contents, and the XML representation of the message would appear in the fourth and final pane.
The tool suffered from the same problem that plagues many internal tools. It wasn’t refined or nice or even very usable. It was always the minimum necessary to get the job done which meant that it was always pretty shitty. It didn’t always work quite right either, especially when a queue would fill up with a significant amount of messages, everything would slow to a crawl. And sometimes the daemon process would just completely crap out, because as you’re probably already aware WCF is such a joy to work with.(Sarcasm intentional.)
I don’t have any idea how many hours I ended up pouring into that tool, but what I do know for sure is that I wasn’t solving any business problems during that time. Meanwhile it was never the tool I wanted or really needed it to be, and addressing its shortcomings was always my lowest priority.
And MsmqRemote even begin to cover everything we needed to effectively monitor a production system. Endpoint health was a big concern. It wasn’t unheard of for an endpoint to appear to be healthy as far as the Process Manager was concerned, but for some reason to have stopped processing messages for whatever reason. I can think of one instance where in retrospect I’m sure my crappy code was to blame – a “command and control” sort of component implemented in an IWantToRunAtStartup that should have been a bunch of never-ending sagas instead. So my IT Manager would create a bunch of monitors in Microsoft SCOM (may have been MOM at the time) based on queue sizes and performance counters and all that sort of stuff. That was really his deal, not mine. But every once in awhile we’d forget to register a new endpoint when it got deployed for the first time, so then the first time it acted up or stalled we’d have to deal with problems like a few million messages backed up in a queue with no warning.
What a pain! If only there was a company out there that understood how distributed systems worked that could make tools to address these issues!
The Service Platform
The whole reason that NServiceBus Ltd. changed its name to Particular Software is that they were developing products to meet these needs, making NServiceBus itself only part of the story.
NServiceBus is now joined by a bunch of friends:
ServiceControl
ServiceControl is a specialized endpoint that lives on the same server as your centralized audit and error queues. It processes every message that arrives in the audit queue (in other words, a copy of every message that flows through your entire system) and stores the details in an embedded RavenDB database. It then discards those audit messages because otherwise you’d be running out of disk space in a hurry. It also reads the messages off the error queue and similarly stores these in Raven, but keeps these message around in a new queue called error.log because you’ll more than likely want to send those messages back to their source queues after you fix the underlying problem.
All this information stored in the embedded RavenDB database is made available via a REST API. (Suck it WCF.) With this API you can build your own reports and tools if you like, but this provides the foundation from which the other Service Platform tools are built.
ServiceInsight
ServiceInsight is a WPF application that makes my little MsmqRemote look like it was written by a 3rd grader, but it extends much deeper than just showing message details and retrying errors. Because it feeds off the ServiceControl API, which is processing the audit messages from ALL your endpoints, it shows a holistic view of your entire distributed system.
When NServiceBus sends or publishes a message in the scope of a message handler, enough headers are added that by the time it gets to ServiceInsight, complete conversations can be stitched together and represented as graphical flows, where sending commands are represented as solid lines and published events are represented as dashed lines.
Check out the flow diagram in this screenshot.
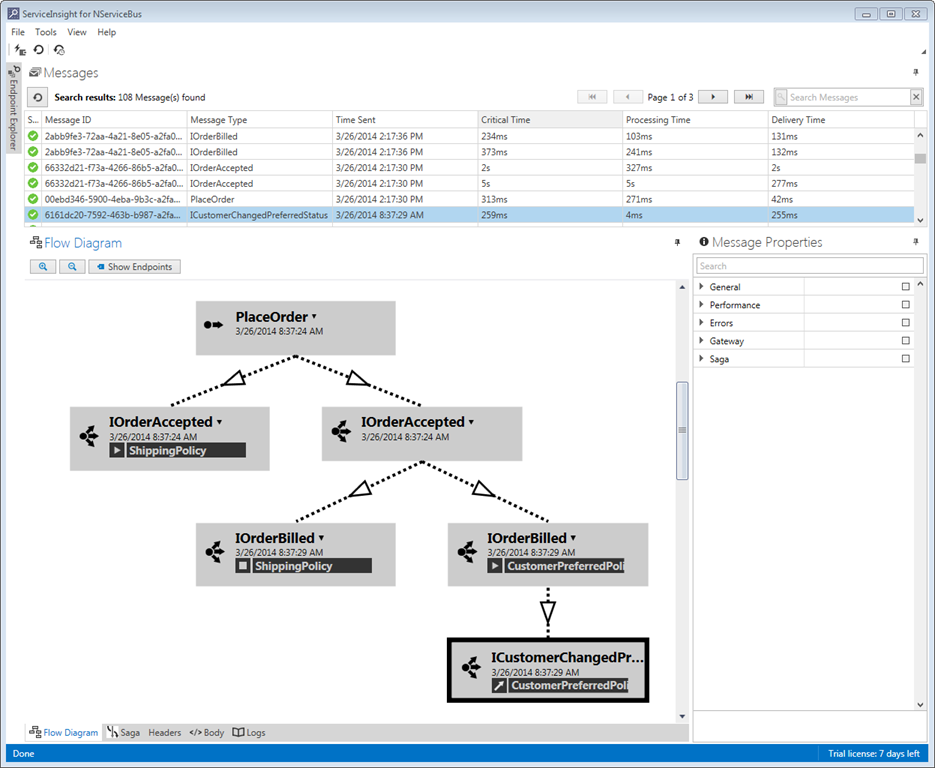
Notice how some of those messages have “policies” mentioned under the timestamp. Those are sagas, and show how the message flow integrates with sagas you write. This is because I’ve included the ServiceControl.Plugin.SagaAudit NuGet Package in my endpoints, which inserts itself into the pipeline to send saga auditing information to ServiceControl.
If you click on one of those, or on the Saga tab near the bottom, you’ll get this amazing visualization showing the saga’s state changes in vivid detail, like this screenshot zoomed to show only the saga flow:
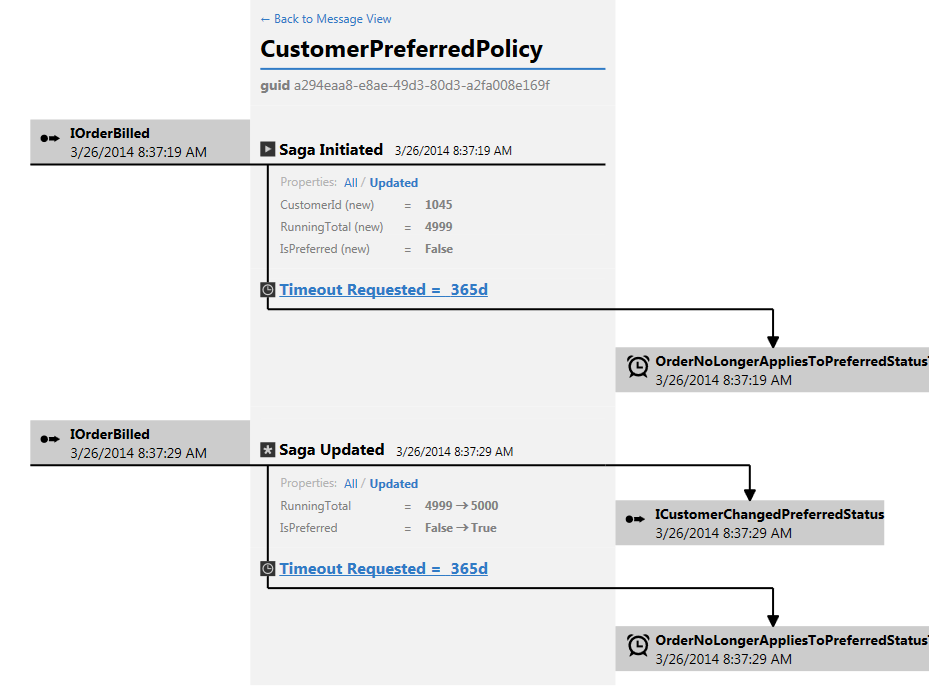
This is pure awesome, and something you’ll only ever have time to build on your own if either 1) you work for Particular, or 2) you work for a company that somehow isn’t concerned with making money. You’re also not going to get this level of tooling from MassTransit. You do, after all, get what you pay for.
ServicePulse
Where ServiceInsight is the tool for a developer to debug a system, ServicePulse is the tool for my IT Manager and our other Ops friends to monitor our systems in production and make sure that everything is healthy.
All you need to do is deploy the ServiceControl.Plugin.Heartbeat NuGet package with your endpoint, and it will begin periodically sending heartbeat messages to ServiceControl. ServicePulse is a web application that will use this information, along with information about failed messages, and serve up a dashboard giving you near real-time updates on system health with all sorts of SignalR-powered goodness.
In addition, you can program your own custom checks to be tracked in ServicePulse. For instance, let’s say you needed to be sure a certain FTP server was up. You could program a custom check for that by including the ServiceControl.Plugin.CustomChecks NuGet package and creating a class that inherits PeriodicCheck.
This is what ServicePulse looks like moments after I stopped debugging in Visual Studio, causing the heartbeat messages to stop.
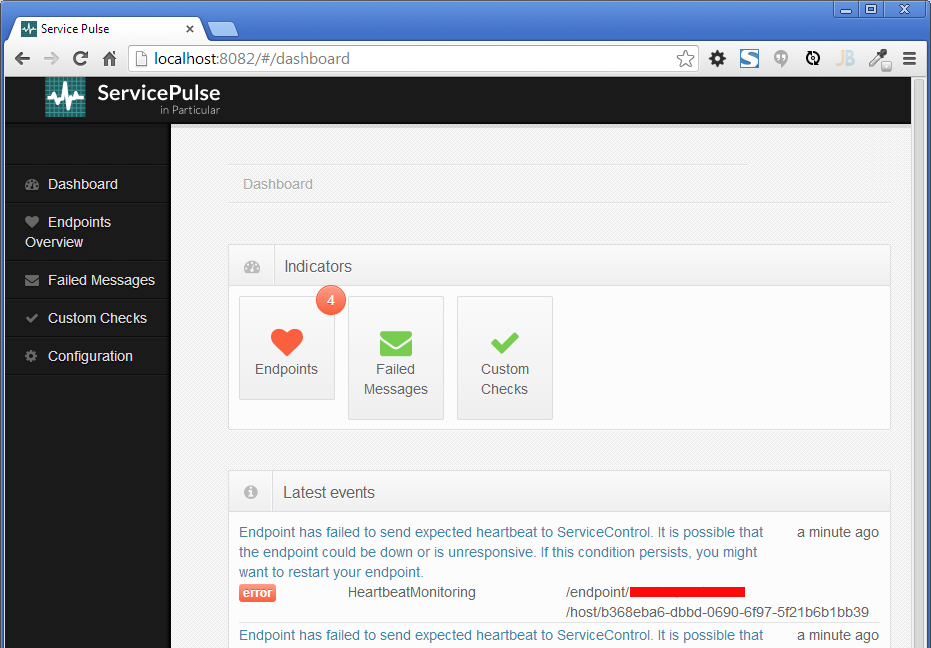
Yes, the Endpoints box bounces when there’s an issue. I guess it’s mad at me! I would show you more screenshots, but they’re full of a recent client’s name and I don’t love image editing that much, plus you should go try for yourself!
The one thing that is missing from ServicePulse, by necessity really, is a direct notification feature. You aren’t going to want your Ops people constantly staring at the ServicePulse website; you need some way for them to be notified when there’s an issue. Every company is going to want to do that differently, of course. Some will want a simple email notification, some will want an SMS, some will want integration with a HipChat bot, and of course some will want all of the above!
It’s convenient that ServiceControl is really just another endpoint. It has an events assembly ServiceControl.Contracts that contains events that you can subscribe to. Check out this sample MessageFailedHandler that shows how you could subscribe to the MessageFailed event and send a notification email.
In the future there will be additional tooling to connect ServicePulse with Microsoft SCOM and perhaps other monitoring suites as well.
ServiceMatrix
This article is mostly about system monitoring, and ServiceMatrix is really not a monitoring tool, but it deserves a mention because it is also a part of the new Service Platform suite of tools.
ServiceMatrix is a Visual Studio plugin that makes it possible to build an NServiceBus system with graphical design tools, dragging and dropping to send messages from one endpoint to another, and that sort of thing. It really deserves an article all to itself.
I’ve been doing NServiceBus the hard way for quite some time, so it’s hard for me to wrap my head around doing it graphically. But the hard truth is that the NServiceBus code-by-hand demo I frequently give that takes about an hour to create manually can be done in about 5 minutes with ServiceMatrix. Five Minutes. Udi himself has stated that now that he’s gotten used to ServiceMatrix, he can’t envision creating NServiceBus solutions any other way.
Aside from creation speed and baking in NServiceBus design best practices, ServiceMatrix contains two features I really feel are game-changers.
First, whenever you debug your solution with ServiceMatrix, it will generate a debug session id that is shared with all your endpoints, and reported to ServiceControl via the ServiceControl.Plugin.DebugSession NuGet Package. It will then navigate to a URL starting with the si:// scheme, which is registered to ServiceInsight, so ServiceInsight will open up and show you details for just the messages volleyed around during the current debug session. This means, in many cases, you won’t need to painstakingly arrange all of your endpoint console windows just right so that you can see what’s going on, you’ll just look at the results in ServiceInsight.
Second, when you create an MVC website with ServiceMatrix, it will auto-scaffold a UI to test sending messages with fields to enter message property values. What a big time saver over creating temporary controllers just to test things out, and having to interact with them only from the query string!
Conclusion
When I think about the old about the crummy tools I built in the past for NServiceBus monitoring in comparison to the new tools in the Service Platform, it reminds me of the difference between my garage and my grandfather’s woodshop. My garage contains a bunch of the basics. Sure I have a couple saws and screwdrivers and a hammer or two, but my grandfather has been retired for several years and in that time has been pursuing woodworking seriously as more than a hobby, so he’s got a dozen saws and the central vacuum system and all the little toys and jigs you need to really get some serious work done. Every time I need to use the table saw I have to back a car out and drag the saw out from the corner, but he doesn’t waste time with that because his whole workshop is set up and ready to go.
Just as I could accomplish so much more in my grandpa’s workshop than in my garage, I will be able to accomplish so much more with NServiceBus using the tools in the Service Platform. They’re exactly the tools I would have built myself (or better) if only I’d had the time.
But I didn’t have to.